Hadoop之MapReduce介绍整理 什么是批处理 在了解MapReduce之前,需要了解批处理的概念,批处理模式是一种最早进行大规模数据处理的模式。批处理主要操作大规模静态数据集,并在整体数据处理完毕后返回结果。...
”hadoop 算法 mapreduce“ 的搜索结果
该项目实现了KNN算法在Hadoop平台基于欧拉距离,加权欧拉距离,高斯函数的MapReduce实现。 特色或创意:实例上添加了基于欧拉距离,加权欧拉距离,高斯函数的实现。 使用的是著名的鸢尾花数据集。据集内包含 3 类...
什么是Hive:专门对大数据进行离线的分析使用的工具适用于数据分析,特征处理等任务,它的底层是把HQL转化为MapReduce程序,并且数据存储在HDFS上,程序运行在yarn上。(经常是深夜的定时任务,处理完后自动存放入...


Hadoop-MapReduce下的PageRank矩阵分块算法 高清完整中文版PDF下载
# 基于Hadoop下MapReduce框架的并行C4.5算法 > 项目来源于**西南交通大学**信息科学与技术学院**计算科学与技术专业**毕业设计 ## 说明 * 程序利用Eclipse EE在Hadoop平台下,使用Map/Reduce编程框架,将传统的C...
人工智能-Hadoop
人工智能-hadoop
MapReduce是hadoop的核心组件之一,hadoop要分布式包括两部分,一是分布式文件系统hdfs,一是分布式计算框,就是mapreduce,二者缺一不可,也就是说,可以通过mapreduce很容易在hadoop平台上进行分布式的计算编程...
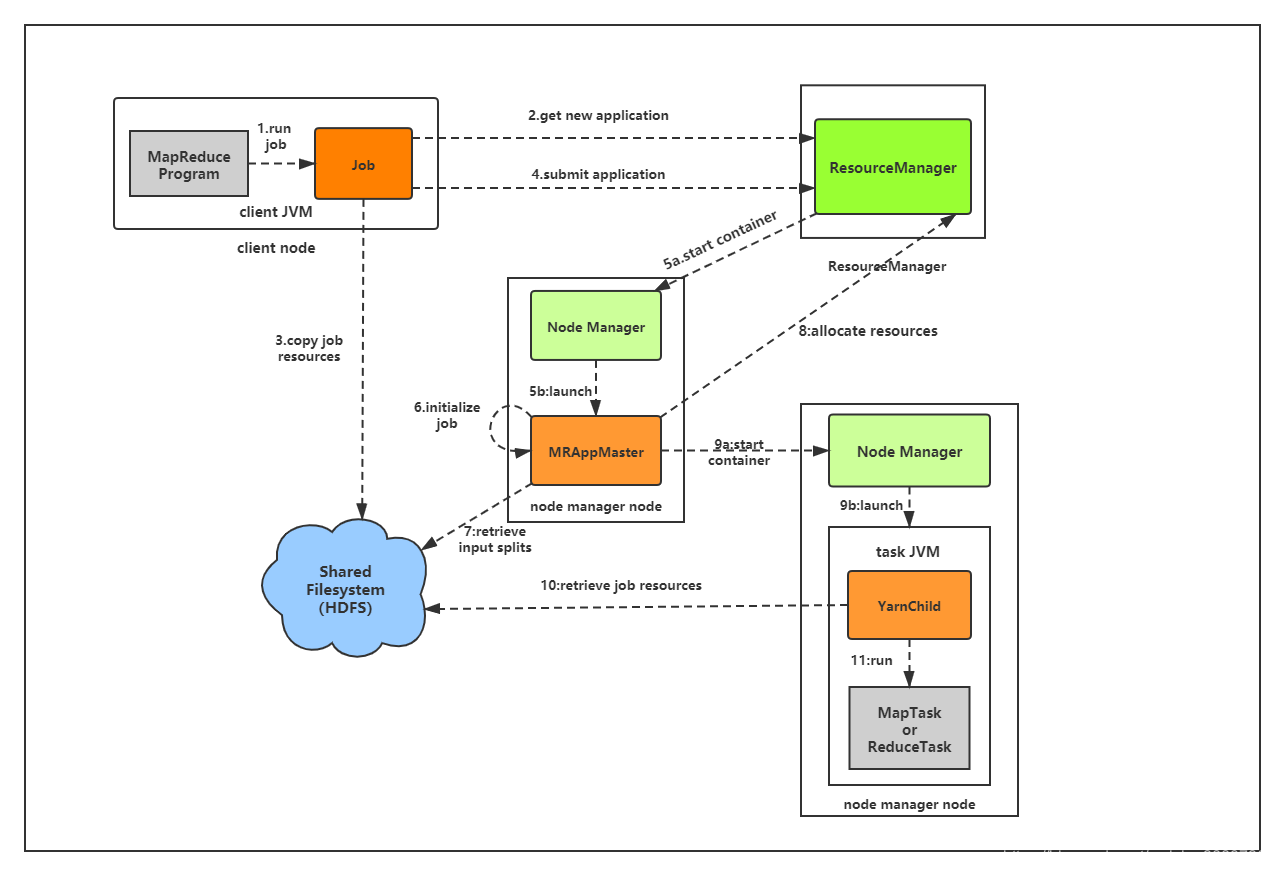
目录 一、 MapReduce概述 1.1 MapReduce定义 ...二、 Hadoop序列化 2.1 序列化概述 2.2 自定义bean对象实现序列化接口(Writable) 三、 MapReduce框架原理 3.1 InputFormat数据输入 3.1.1 切片与MapTas
第1章 MapReduce概述 1.1 MapReduce定义 1.2 MapReduce优缺点 1.2.1 优点 1.2.2 缺点 MapReduce核心思想 MapReduce核心编程思想,如下图 1)分布式的运算程序往往需要分成至少2个阶段。 2)第一个阶段的Map...
一、Hadoop简介 Hadoop最早只是单纯的值分布式计算系统,但随着时代的发展,目前hadoop已成了一个完整的技术家族。从底层的分布式文件系统(HDFS)到顶层的数据解析运行工具(Hive, Pig),再到分布式协调服务...
hadoop之MapReduce的一些简介,架构和分析
Hadoop_MapReduce 使用Hadoop进行大数据处理 该项目在Hadoop框架上使用Map-Reduce从零开始实现基本的文本处理任务,例如字数,n元语法,倒排索引,关系连接和k近邻算法。

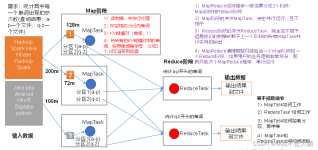
一、MapReduce数据处理流程 关于上图,可以做出以下逐步分析: 输入数据(待处理)首先会被切割分片,每一个分片都会复制多份到HDFS中。上图默认的是分片已经存在于HDFS中。 Hadoop会在存储有输入数据分片(HDFS中...
如果使用某一个字段进行辅助排序,那么这个字段"必须"在之前"有过排序"的处理,所有"辅助"顾名思义就是在前者排序好的基础上发挥的作用, 单独使用的辅助排序 很可能生成的结果顺序是乱的,最好不要使用。...
hadoop基于MapReduce实现TFIDF算法完成热点词汇抓取首先了解TFIDF环境步骤开始 首先了解TFIDF TF-IDF的主要思想是,如果某个词或短语在一篇文章中出现的频率TF高,并且在其他文章中很少出现,则认为此词或者短语具有...
通过充分利用分布式计算,Hadoop实现了对大规模数据的高效处理,使得复杂的数据分析任务变得...通过这一实践案例,我们可以深入了解Hadoop的MapReduce编程模型,以及如何在实际应用中利用其优势来处理和分析海量数据。

MapReduce模型 | Hadoop MapReduce的基本工作原理
Elephant56是用于Hadoop MapReduce的遗传算法(GA)框架,旨在简化分布式GA的开发。 它提供了可以由开发人员重用的高级功能,而开发人员不再需要担心复杂的内部结构。 特征 顺序遗传算法 并行遗传算法 全局模型,也...
本篇博客原理部分摘取自...(如果有不理解的可以直接查看上面的链接,另外说一下,该博客只能帮助你理解mapreduce的原理,如果你接触过相关开发的话,本博客可能并不能给你带来帮助。) MapReduce思想 MapReduce思想...


基于Apriori算法的频繁项集Hadoop mapreduce.rar

推荐文章
- 产品周报第33期|完善铁粉规则,优化原创保护策略,升级创作中心的数据展示,开放业界专家自定义域名权益……_创作者中心铁粉数0-程序员宅基地
- 自建网盘之 NextCloud 终极记录-程序员宅基地
- C语言最重要的知识点(复习、期末考)-程序员宅基地
- Windows11系统开机跳过联网全过程(详解)_跳过联网进入win11 需要设置密码-程序员宅基地
- SpringBoot 整合RabbitMQ错误记录-程序员宅基地
- 【线性代数笔记】正交矩阵的性质-程序员宅基地
- AndroidStudio4.0 Layout界面预览设置等_android studio layout预览设置-程序员宅基地
- <转载>Android 对sdcard操作-程序员宅基地
- BDC报错信息查看-程序员宅基地
- AS 3.1.3连续依赖多个Module,导致访问不到Module中的类_为什么as在一个包下建了多个module,缺无法打开了-程序员宅基地